What the Heck is Durable Execution?
Context
Let’s imagine that you have a following process:
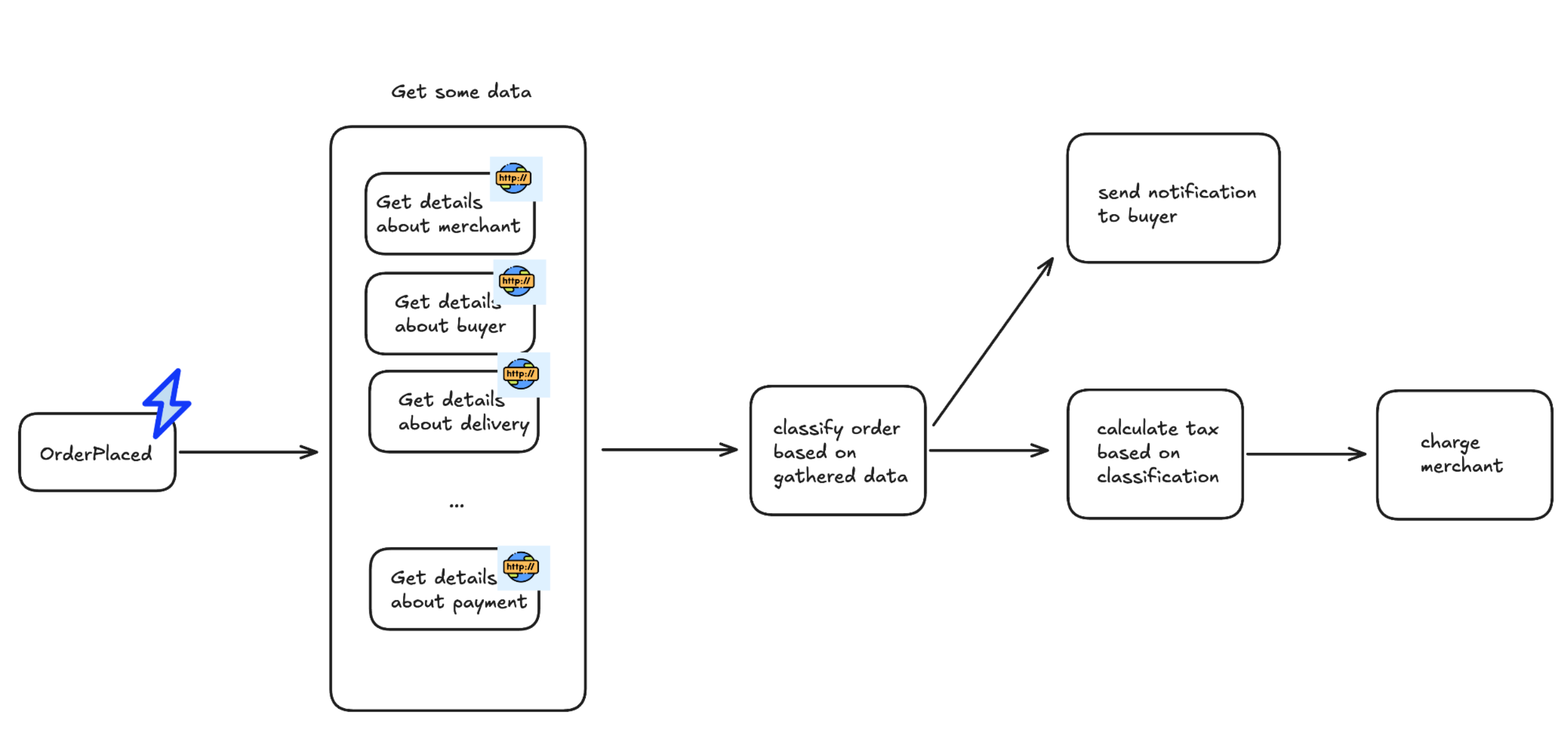
- Some hook comes to you like Order Placed
- You gather data from some resources
- You do some actions based on received data
- You publish some results / apply changes to outside world
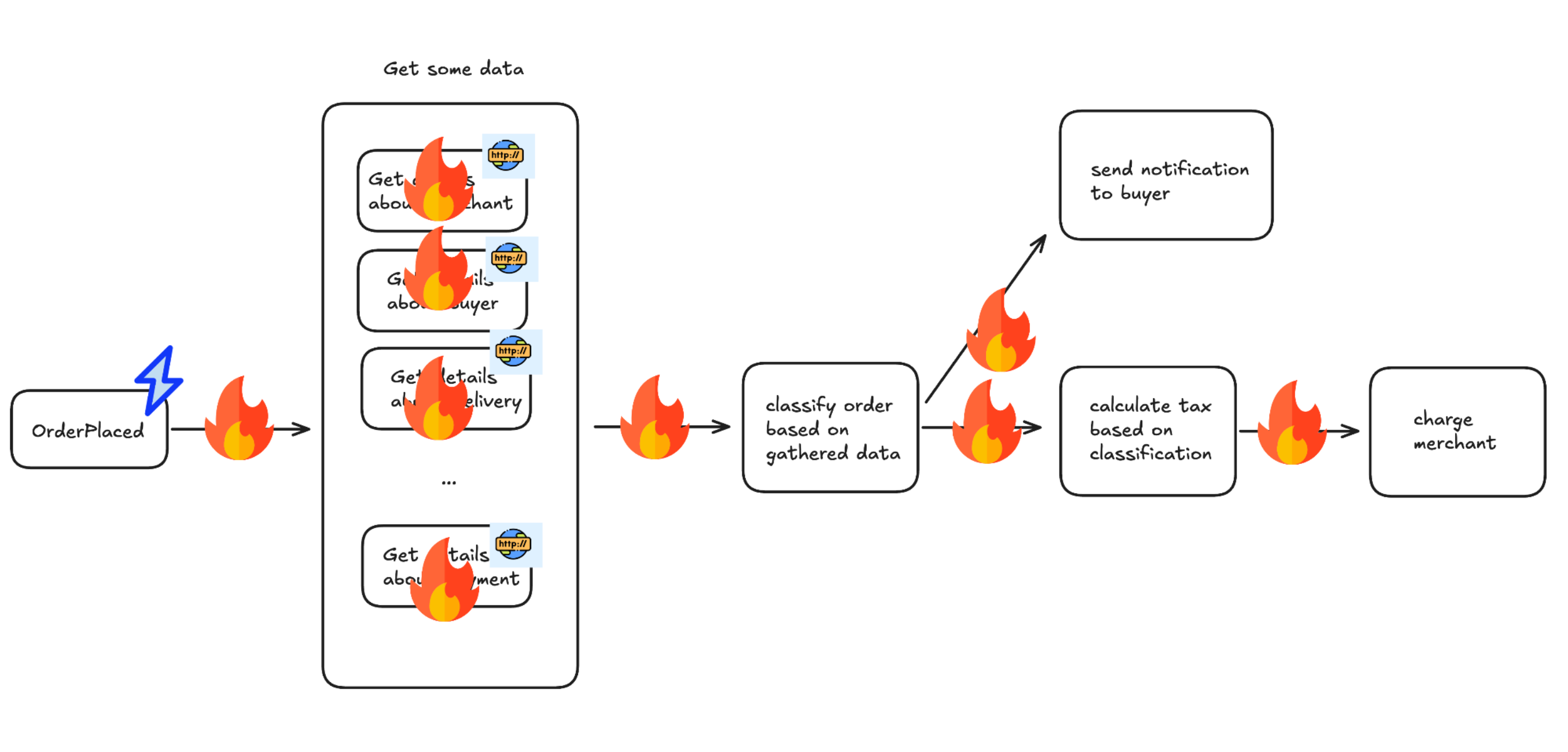
There is an astonishing amount of potential problems in scenario like one above:
- Machine failure at any place of whole process
- Getting details involves communication over network with other services - timeouts, missing data or just casual 5xx because of random reasons
- There may be some edge case not handled by implementation and some failure happens (like exception in JVM)
- If retries incorrectly implemented - things like notification sent twice or mechant charged twice
- Data may be lost and after some step the process is not being continued
- …

In this blog post I’ll write about two solutions for this problem that I’ve encountered:
- Custom made with the queue and tasks - the one I’ve seen applied with success on a big scale
- Temporal.io - the one that I think would save me a lot of headaches if I knew it earlier :)
So Durable Execution is a way of making sure that such process can survive and even if failures happen on the way - it will be eventully handled without any surprises.
Queue and tasks solution
On high level this solution is pretty easy to understand:
Task Scheduler - the idea is to persist all the needed data about the task that will be executed eventually and its metadata (like when it should be scheduled, last failure reason, amount of retries etc.). Then we are polling for tasks not yet finished successfully. Then we pass such a task to Task Handler which executes all the needed steps. If task fails - it will be picked up by scheduler later on. If node crashes - task won’t be marked as finished, so after some time it will be picked up once again.
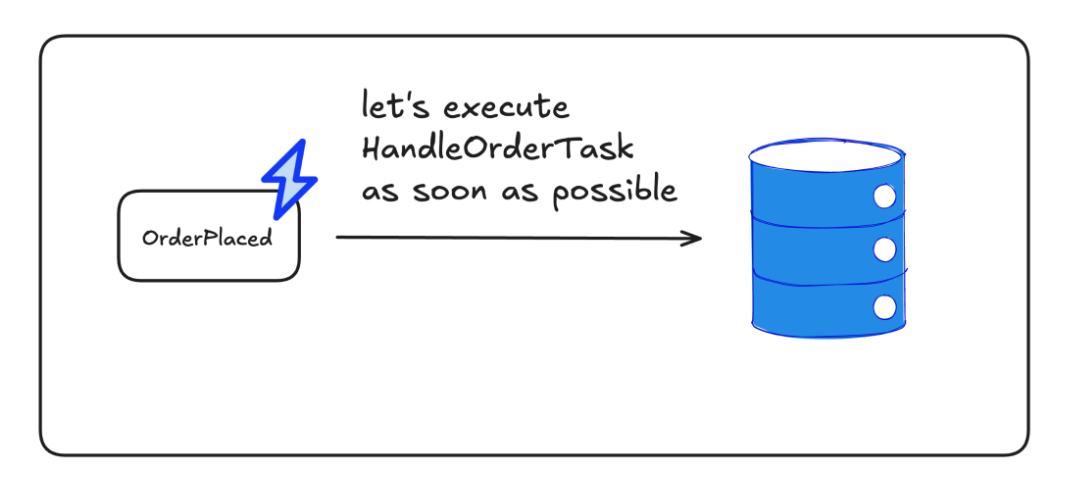
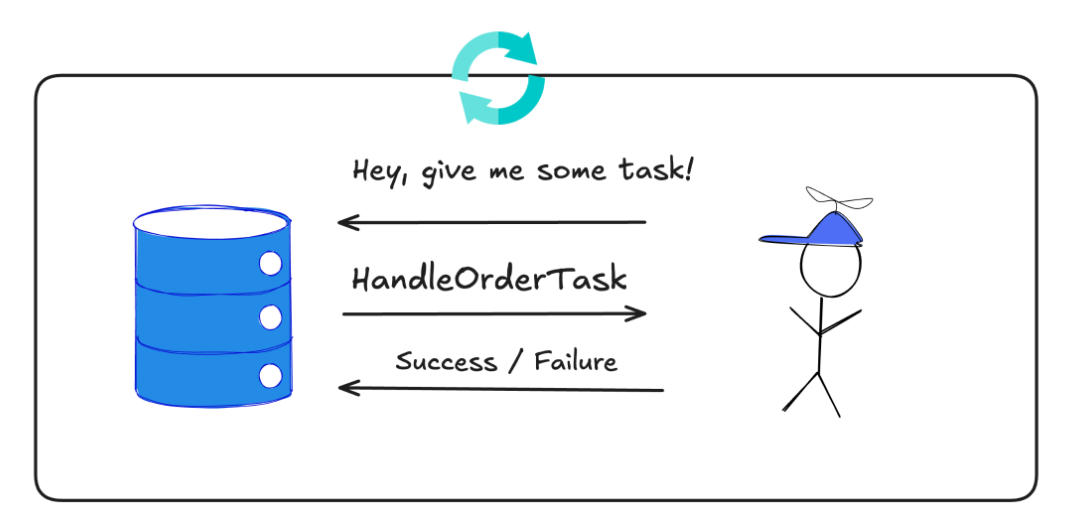
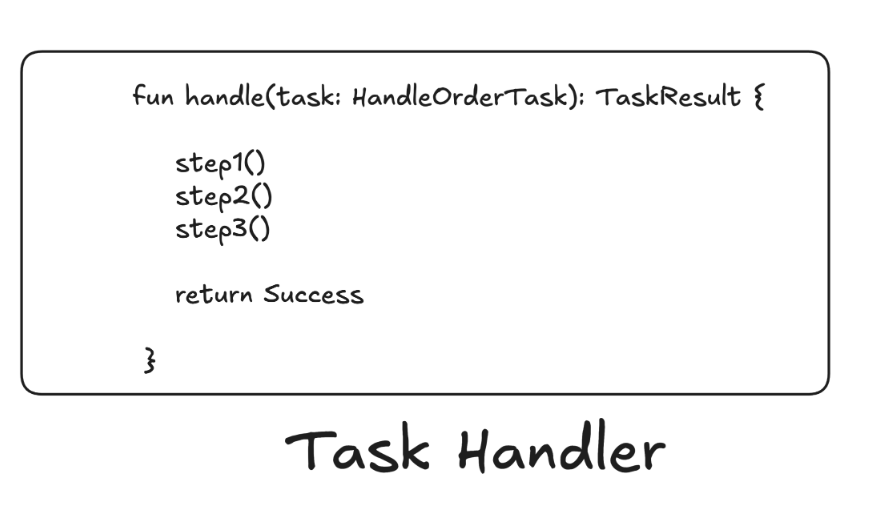
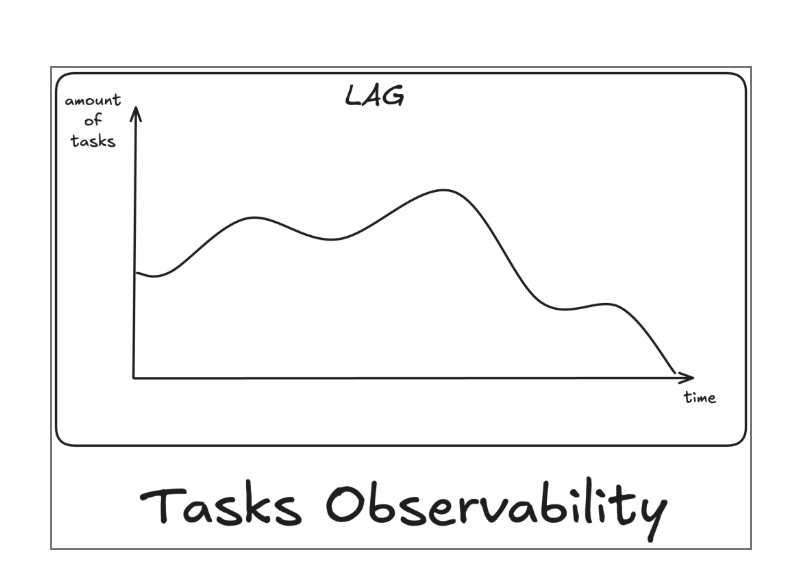
With this approach it’s quite easy to get some nice Observability like how many tasks were not processed yet, what is the longest time for task to stay in the queue, what is the p99 time of task processing etc.
The role of queue may play anything that can store data. I’ve seen nicely working implementation with MongoDB and PostgreSQL and I’ll be focusing on these two. With message broker like Kafka / RabbitMQ it would work bit differently when it comes to details and I don’t focus on them in this blog post.
Challenges
Even if high level overview is simple to understand, implementing such a system isn’t something trivial. Let’s go through some challenges that may wait for you when doing it.
How to ensure that task is executed only once?
The trick is to lock tasks for some time and query only those that are not locked. In MongoDB you can achieve it with atomic operation findAndModify, in PostgreSQL you can SKIP LOCKED. In both cases you can set task status to IN_PROGRESS or change lockedUntil column.
For how long task should be locked? If instance fails and don’t report task progress - how do you know that instance failed and it’s not the case where it’s just processing the task incredibly slow? Probably timeouts are reasonable in such case.
In case of multi-instances setup and single queue you also need to make sure that instances don’t have too much conflicts when polling for tasks. One interesting solution I saw for this (in case of MongoDB acting as a queue):
- there is a table/collection where each instance registers and gets its unique id (1,2,3 etc.)
- find a hash function that maps taskId to instance id
- each instance queries the same amount of tasks (for example 20 tasks each time)
- instance is aware that it has id - let’s say ‘1’ - so it queries only for tasks it “owns” adding condition
(hash(task_id) % 3 = 1)to query (or filtering tasks in memory)
With PostgreSQL acting as queue FOR UPDATE SKIP LOCKED may be enough :)
How to ensure that none of steps is repeated?
If you have transactions available and can fit the whole task execution into transaction - then you don’t need to worry too much. Any failure will just not commit changes to db.
If transactions are not available (I know that even MongoDB has transactions available now, however I’m not sure if they perform well) - things get bit more complicated. You end up having checks before each step was it already executed? which maybe annoying (and it’s not that hard to forget about adding such check!).
How to ensure that some tasks aren’t starved and queue doesn’t block?
So let’s say you have lot of failures. How do you prioritize which task should be executed - the new one or rather the one that failed already 20 times? It really depends on the application but it has to be considered. We touched retries already - it’s necessary to think about retry strategy, task discards and cleanup of successful tasks.
How to make this processing fast?
Most probably you don’t want to process only single task at time. In case of JVM you want to have some thread pool that would handle jobs or you may be using coroutines with Kotlin and run them in parallel. It takes some config tweaks before coming up with optimal setup. Having metrics about task processing but also system usage is necessary here to make steps in the right direction with configuration tweaks.
These are top challenges that come to my mind. Thankfully, in JVM world there is handy library doing lot of this already: db-scheduler. There is also JobRunr but if I recall correctly, free version lacks basic features and it pushes you to buy enterprise one which I never tried out.
Temporal.io
Recently I was reading A Couple Million Lines of Haskell: Production Engineering at Mercury. Beside many intereting insides, the one especially caught my attention:
Temporal is our durable execution framework, and adopting it was one of the better infrastructure decisions we have made. You write your workflow as ordinary sequential code, and the platform records every step in an event history. If a worker crashes mid-workflow, another worker replays the deterministic prefix to reconstruct the state, then continues from where it left off. Retries, timeouts, cancellation, and error handling are provided by the platform rather than each team reimplementing them poorly.
When I saw that then I thought: oh, so probably it’s something like the queue and tasks solution I already know.
Experiment
I wanted to experience it so I found out an example where it could be useful (ok, fair, it’s a bit far-fetched example, but allowed me to play with temporal.io).
So recently I was working on fetching some data from Google Places Api (Search Nearby).
This API requires from caller passing circle as an argument (center expressed in lattitude and longitude and radius). Also, it returns max 20 POIs. (Point of Interests). If there is more than 20 in selected area - you need to split it into smaller areas. In dense cities you still may have more than 20 places even for very small circle - so you end up filtering these circles by categories. So if you want to get data for a bigger area, you end up making lot of quries for small radius circles (and some of them are queried few times for different POI categories).
Well, since it’s paid API and such data is incredibly valuable and hard to get from somewhere else - it makes sense that they don’t make it more convenient.
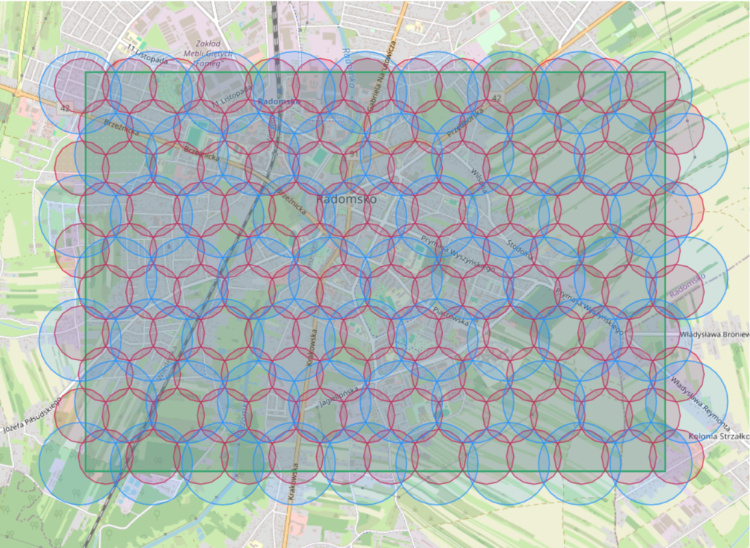
So let’s say I have to query 1000s of circles. What can go wrong?
- Machine failure at any place of whole process (after 2nd or 99th or any circle assuming I’m fetching them sequentially)
- Getting details involves communication over network with other services - timeouts, missing data or just casual 5xx because of random reasons
- There may be some edge case not handled by implementation and some failure happens (like some unexpected data causing process to crash)
- If retries incorrectly implemented - things like overfetching may happen (which may cause additional billing)
- Data may be lost and after some step the process is not being continued
- …
Yup, it’s mostly copy paste from the beginning of this blog post - the problems seem similar.
Step by step setup with temporal.io
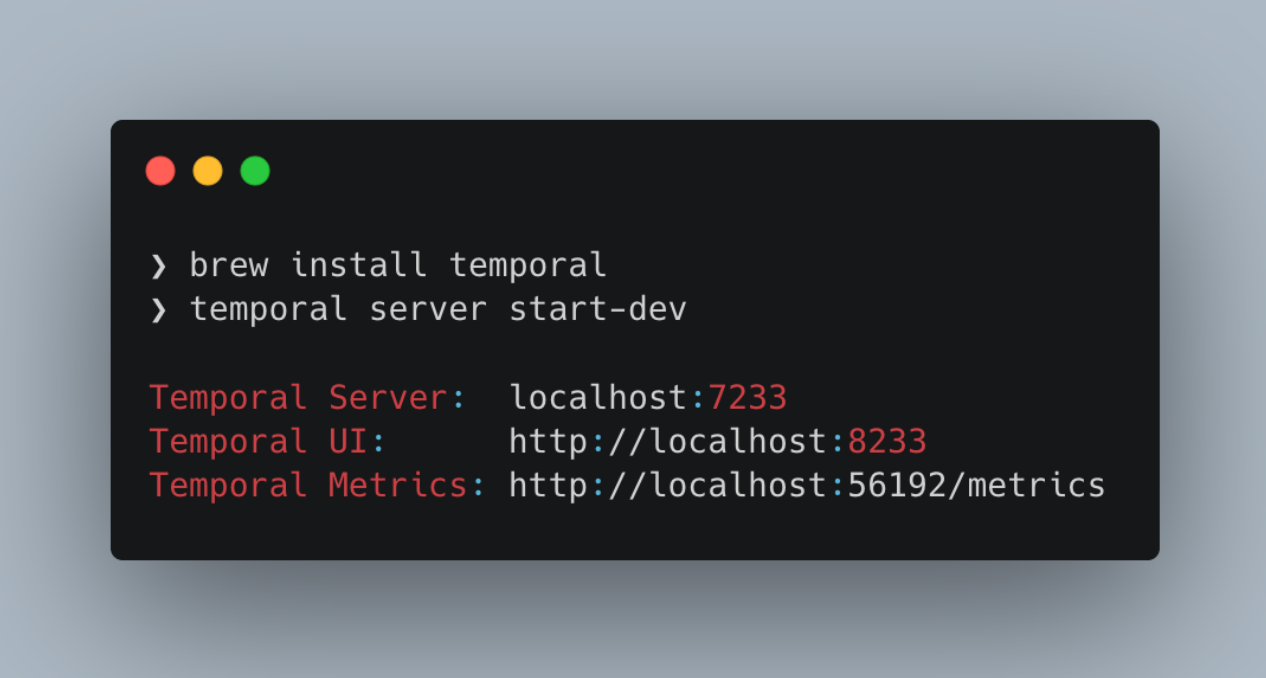
That’s all what it takes to have temporal running locally (for dev purposes). It comes with nice UI, server and loooot of metrics in prometheus format.
Workflow
Then I need to define my workflow: what I want to happen regarding errors on the way.
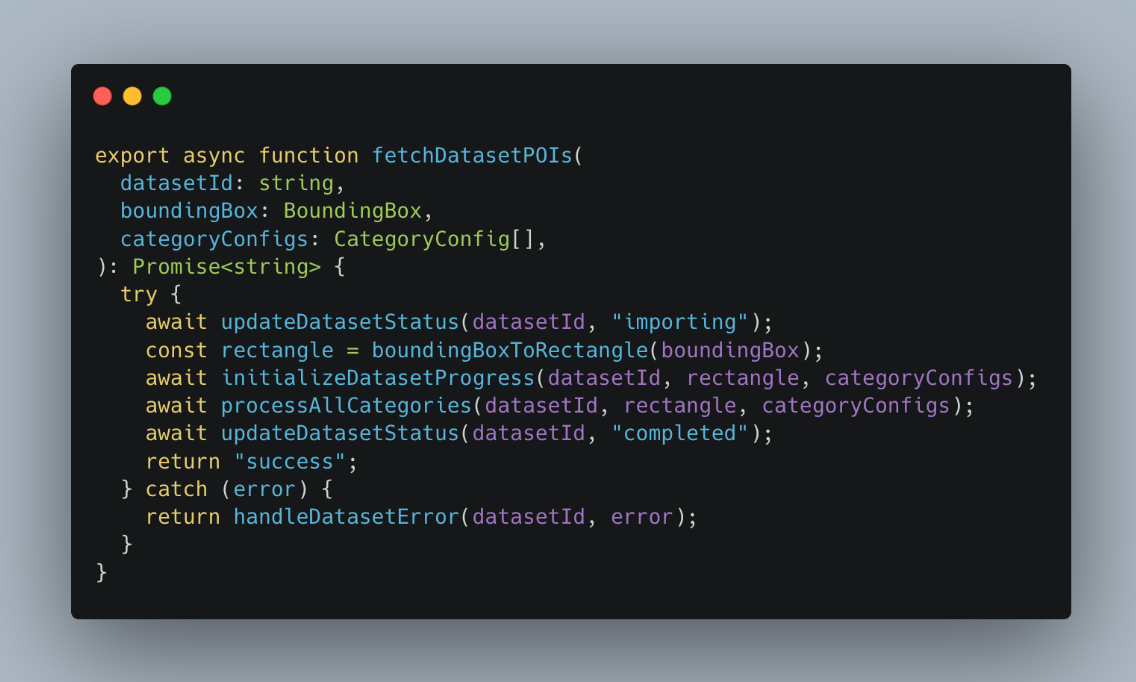
And somewhere below is actual fetching data for given circles:
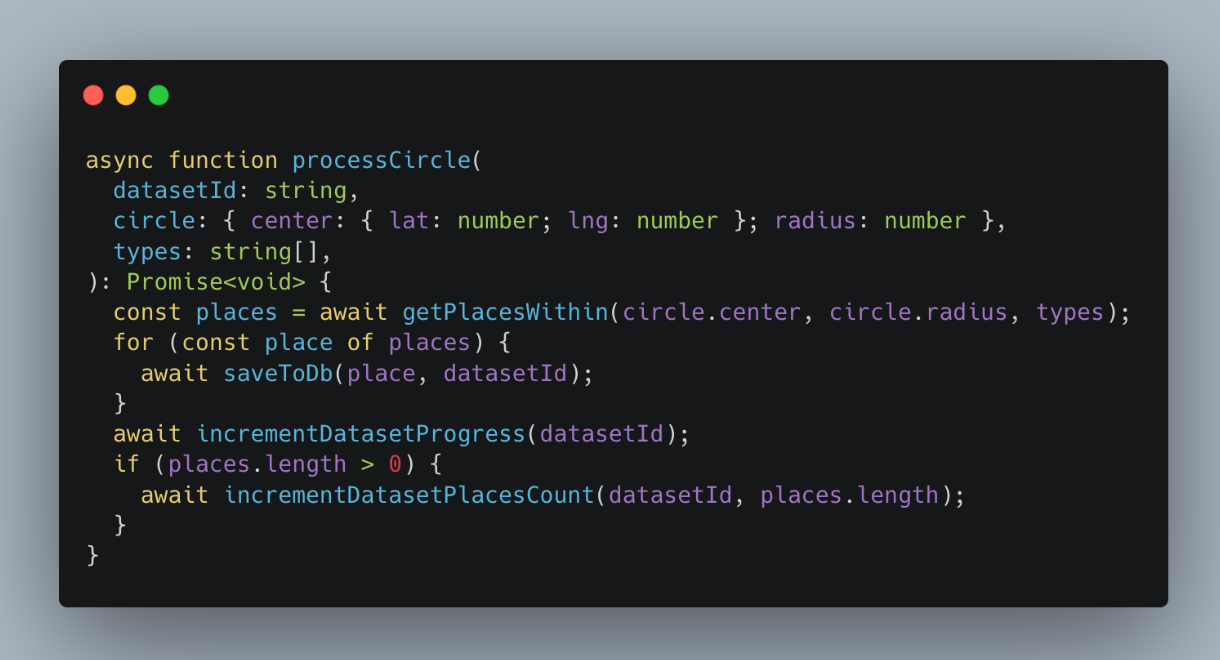
Wait, Piotr! Until now you’re just showing me a plain NodeJs code!
Yup, workflow is just that. The only thing different is that it calls proxyActivities. In this toy example these are activities:
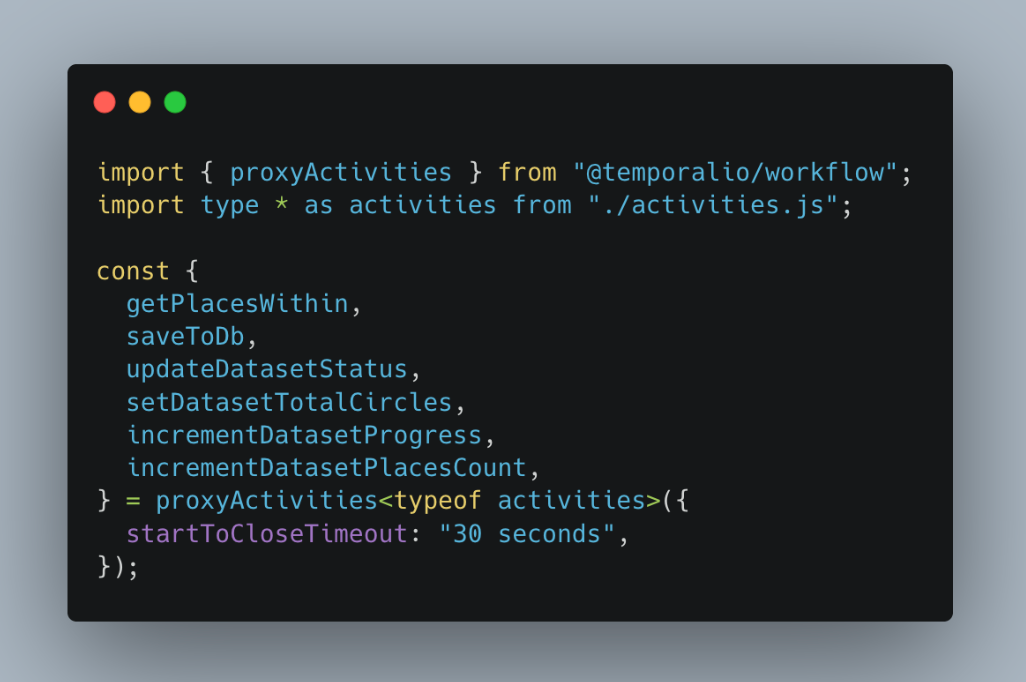
And what the heck is activity?
Activity
Activities encapsulate business logic that is prone to failure, allowing for automatic retries when issues occur.. It comes straight from tepmoral.io docs. Well, we can have different understanding of what business logic is, however the key is that it encapsulates things prone to failure like:
- interaction with some service over network
- saving something to database
- making some expensive calculation that may fail for some reasons
Let’s take a look at getPlacesWithin:
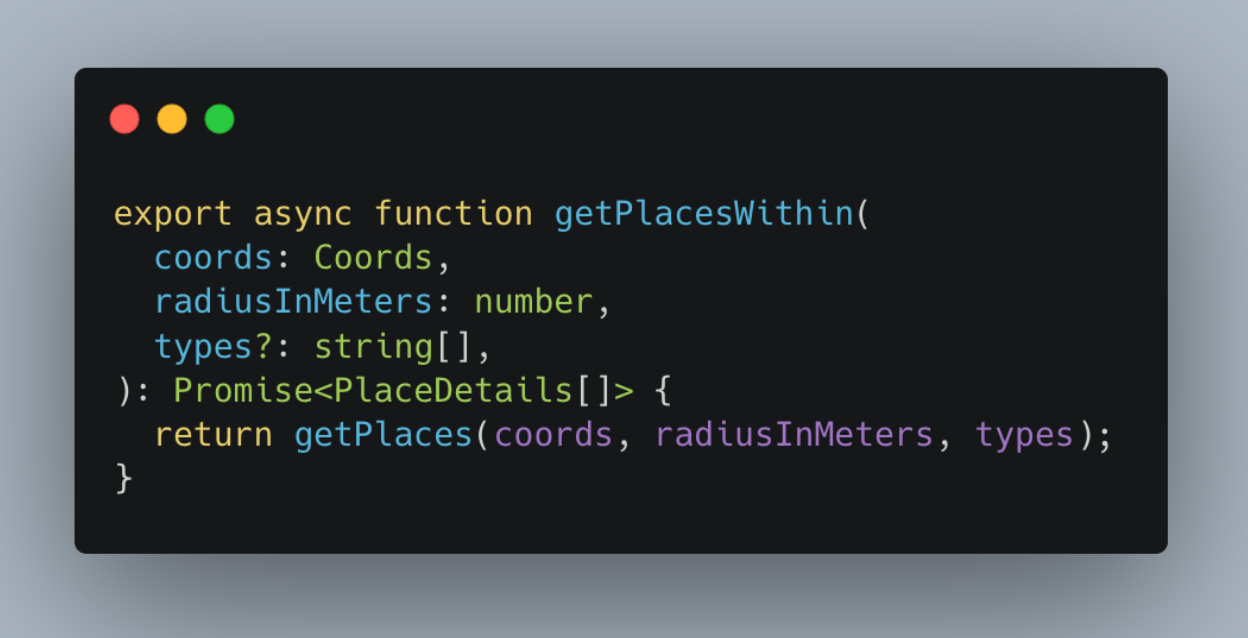
and getPlaces under the hood is just a call to Google Api. So again - simple NodeJs code.
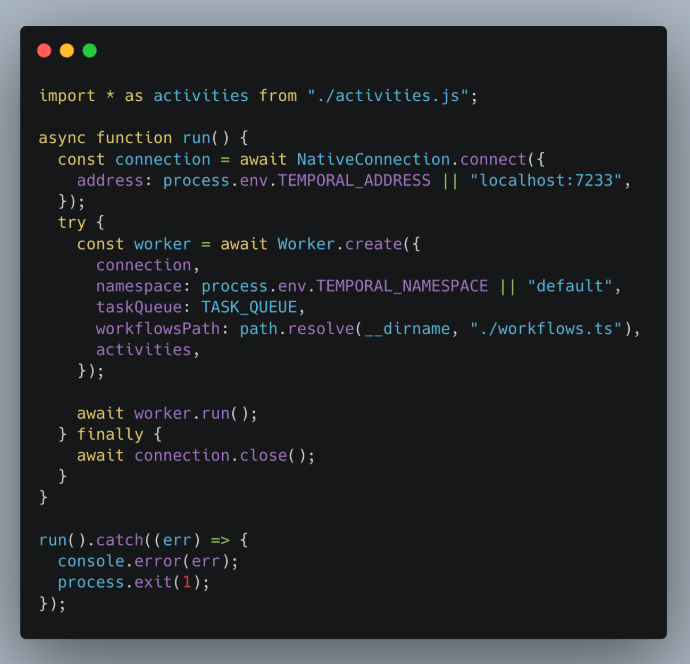
Worker
The last piece of the puzzle is worker. You may run one or more of these. They get workflows and activities to be processed from the queue and process them. Basic config looks like this:
Running the whole machinery
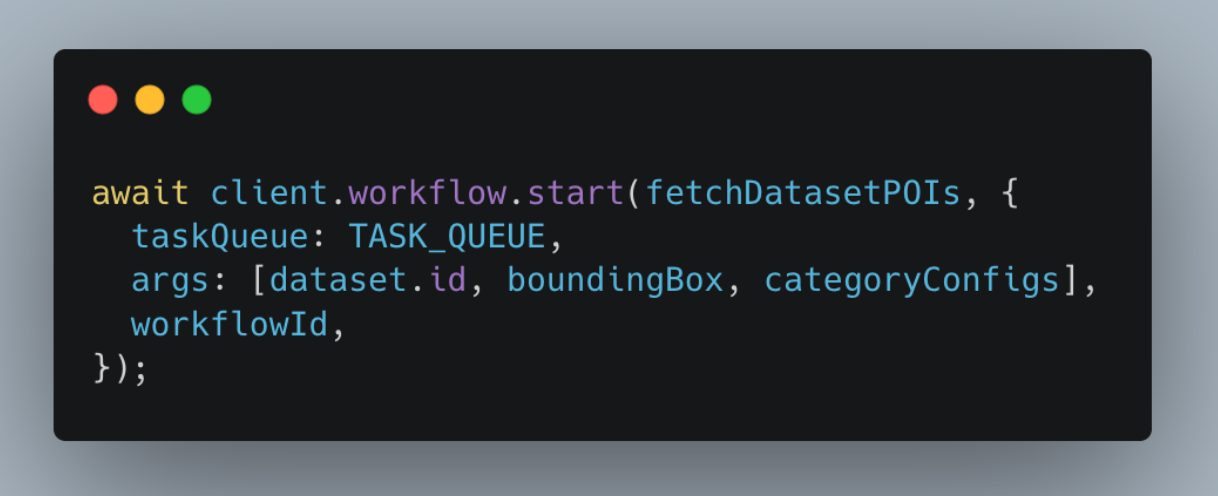
You can run workflow with simple gRPC call, for example in NodeJS with use of temporal sdk:
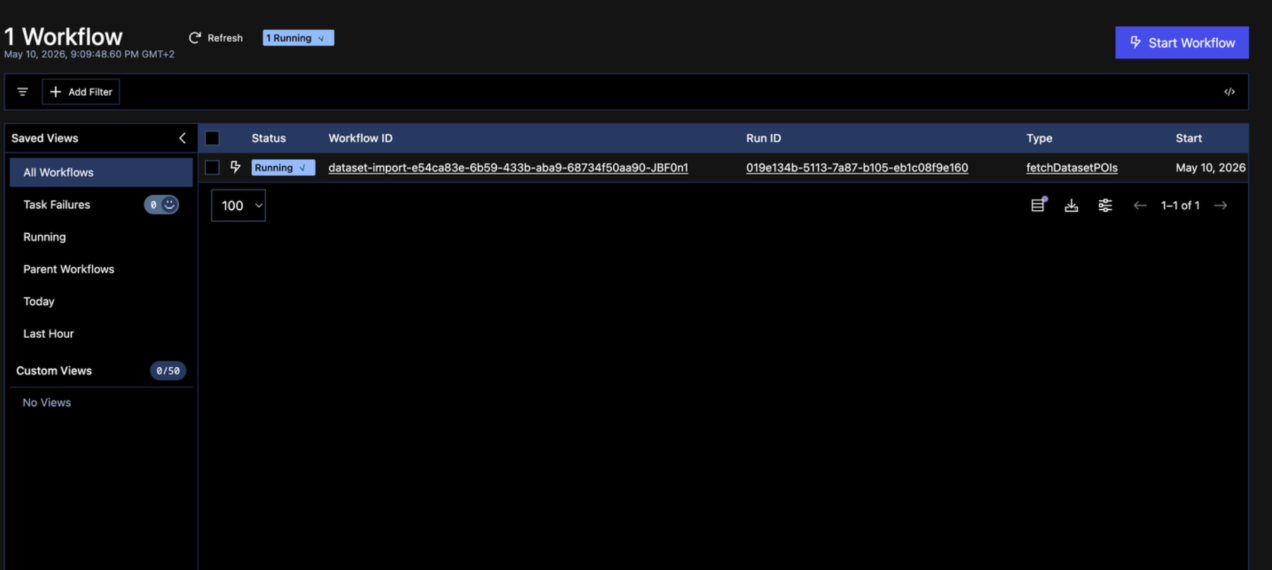
Here are self explanatory screenshots what happens next:
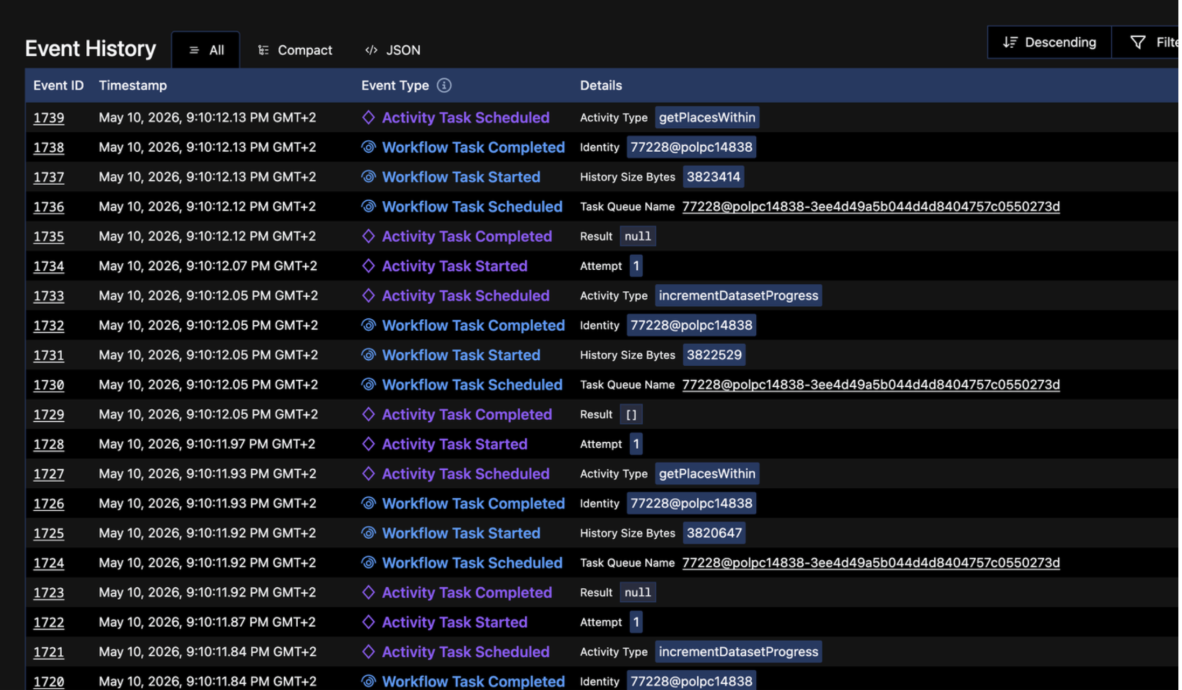
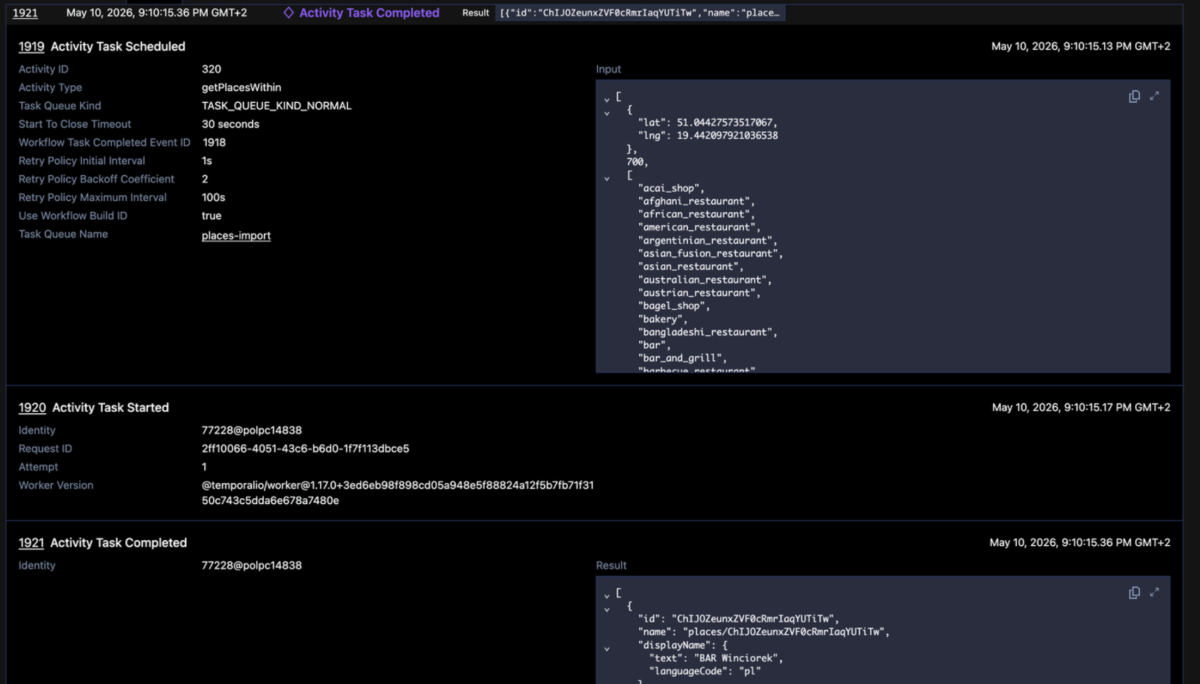
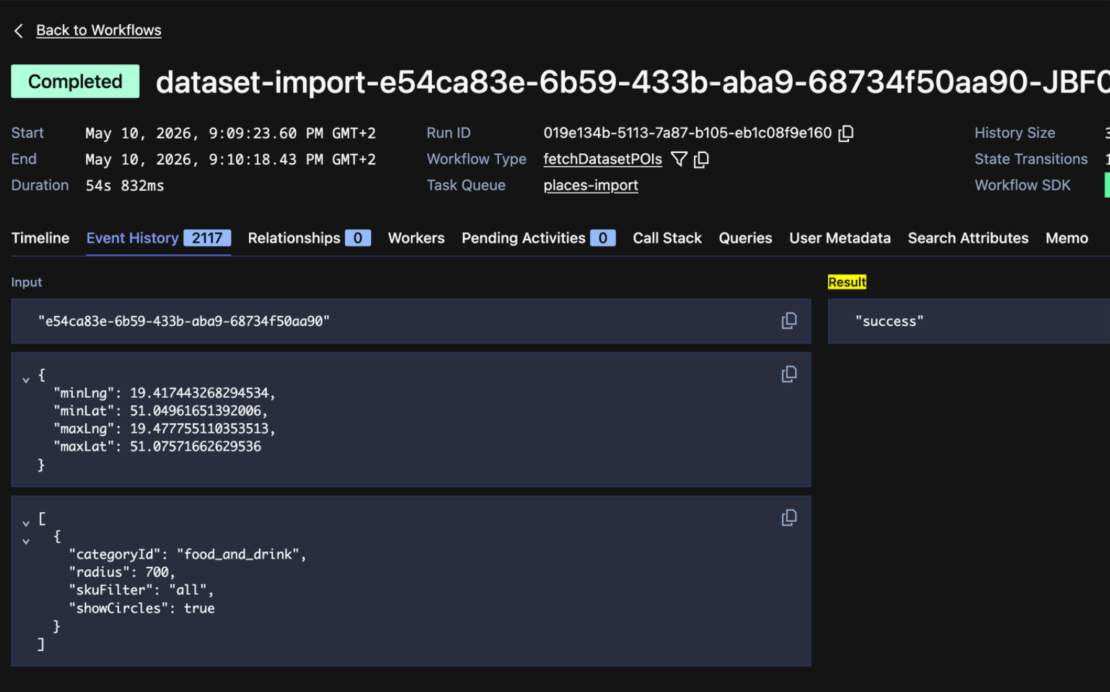
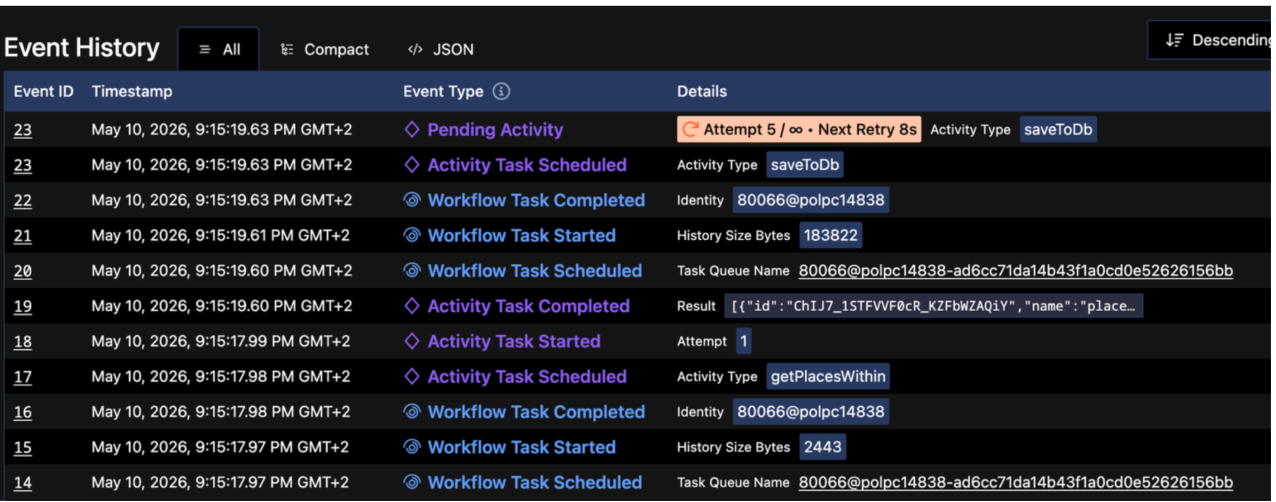
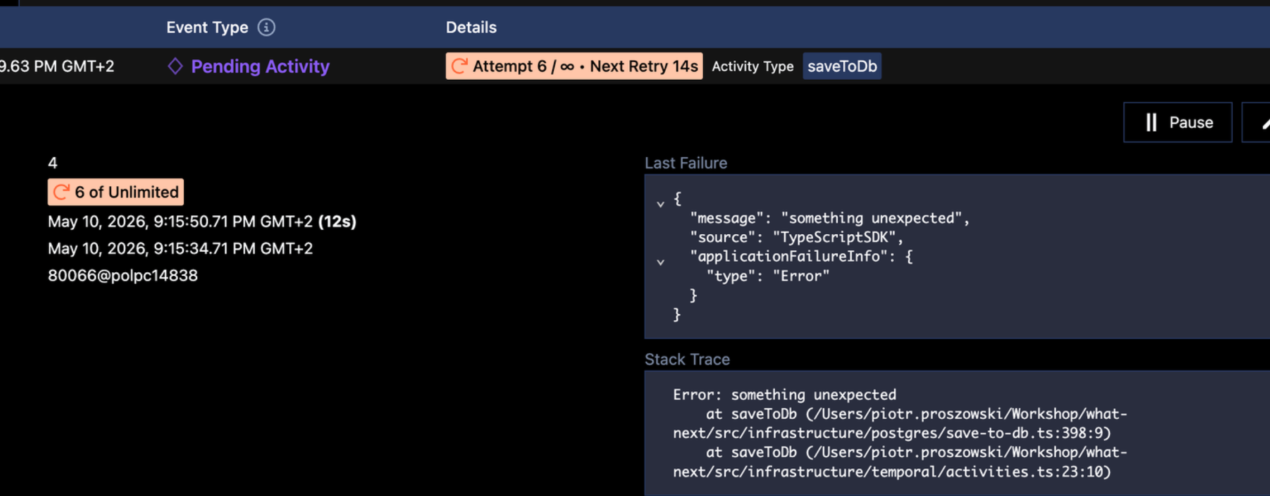
And if something goes wrong?
What I’m impressed with
How easy it was to setup durable execution with Temporal.io for this toy project. I assume there may be challenges when setting it for production cases, but it showed me how DX can be incredible when abstractions are done right!
Look at this history - I have a very granular way to see what happened at every step. What was the input? What was the output? What went wrong in case if something failed. I can control retries and I get metrics out of the box like “how long workflow waits for worker”.
What I’m still curious about
I wonder where is the catch. For sure would need to check how temporal.io behaves under bigger load and if it’s easy to maintain. But for now - it seems like it can save a lot of headaches.
Recently I saw few posts saying “you don’t need external system for durable execution, library is all you need”. One source of such posts is dbos - didn’t try it yet, but will let you know if I do ;)
That’s all for this post. How do you deal with such problems? Do you have any experience with temporal.io? If yes, then I would love to hear about it!
Comments